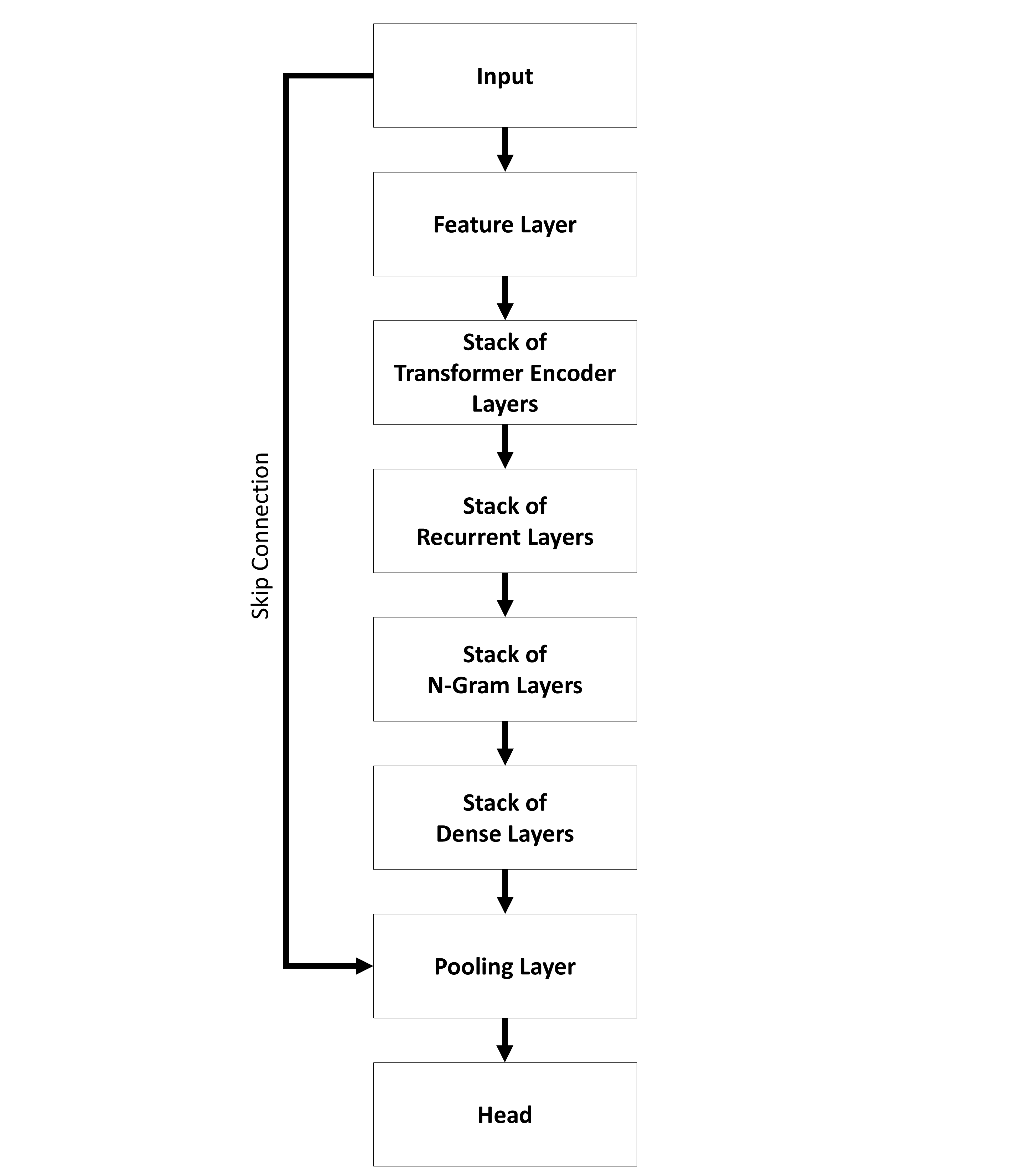
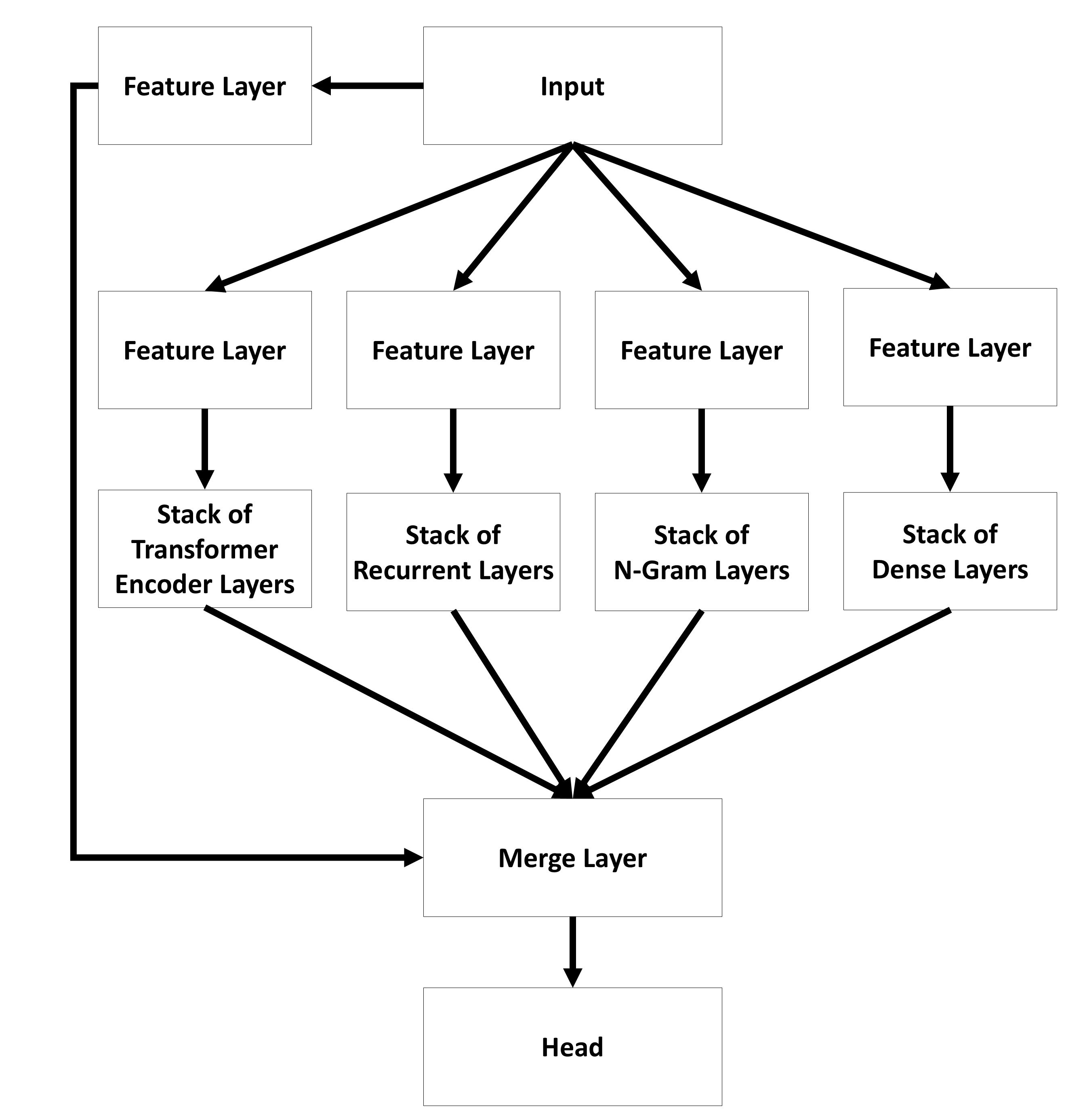
A01 Layers and Stacks
Florian Berding, Yuliia Tykhonova, Julia Pargmann, Andreas Slopinski, Elisabeth Riebenbauer, Karin Rebmann
Source:vignettes/a01_layers_stacks.Rmd
a01_layers_stacks.RmdLayers
Transformer Encoder Layers
Visualization
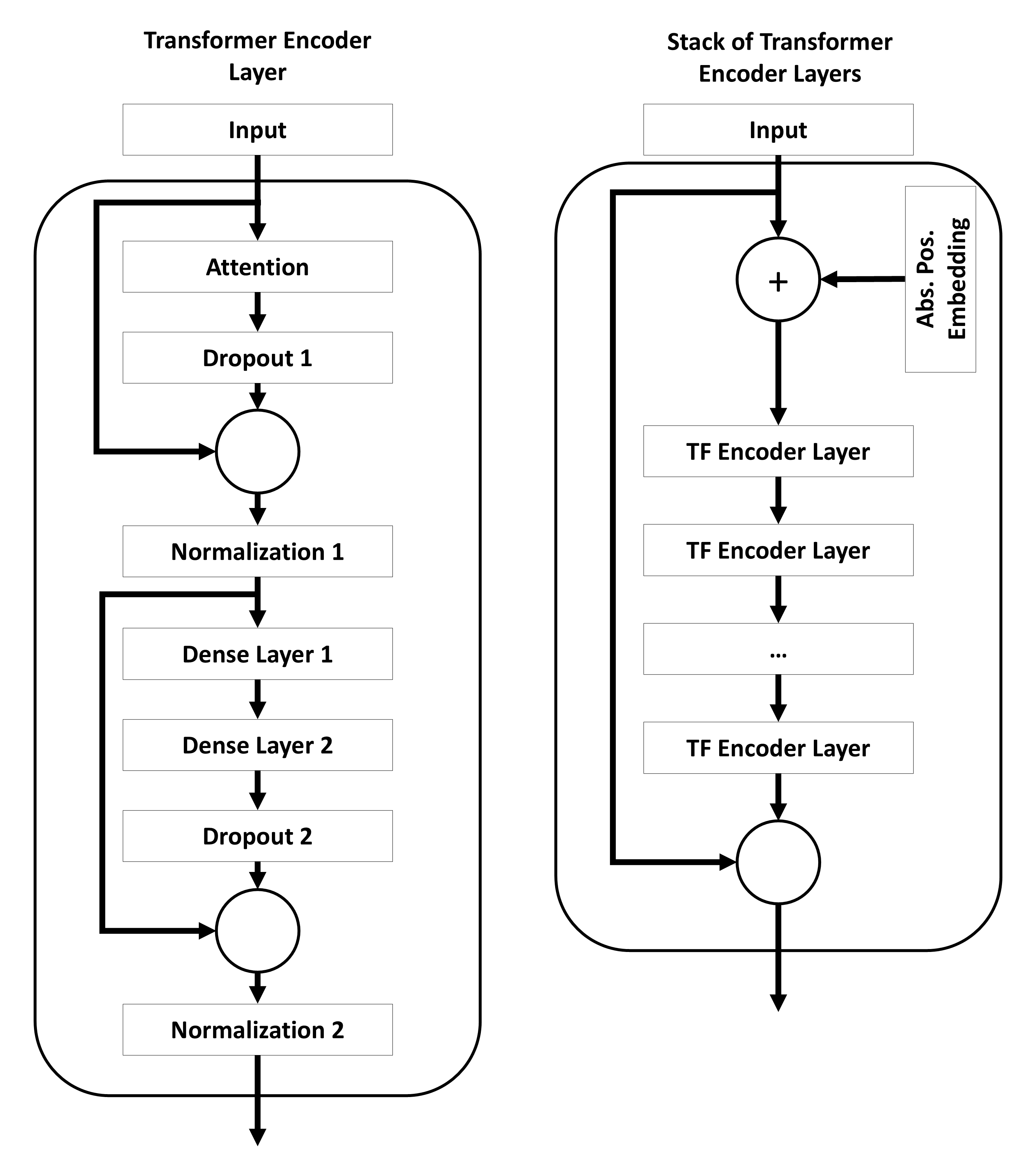
Description
The transformer encoder layers follow the structure of the encoder layers used in transformer models. A single layer is designed as described by Chollet, Kalinowski, and Allaire (2022, p. 373) with the exception that single components of the layers (such as the activation function, the kind of residual connection, the kind of normalization or the kind of attention) can be customized. All parameters with the prefix tf_ can be used to configure this layer.
Parameters
-
tf_residual_type: Type of residual connenction for all layers and stack of layers. Allowed values:
-
'None': Add no residual connection. -
'Addition': Adds a residual connection by adding the original input to the output. -
'ResidualGate': Adds a residucal connection by creating a weightes sum from the original input and the output. The weight is a learnable parameter. This type of residual connection is described by Savarese and Figueiredo (2017).
-
-
tf_normalization_type: Type of normalization applied to all layers and stack layers. Allowed values:
-
'LayerNorm': Applies normalization as described by Ba, Kiros, and Hinton (2016). Implementation supports masking of sequences. -
'BatchNorm': Applies normalization as described by Loffe and Szegedy (2015). Implementation supports masking of sequences. -
'RMSNorm': Applies normalization as described by Zhang and Sennrich (2019). Implementation supports masking of sequences. -
'PowerNorm': Applies normalization as described by Shen et al. (2020). Implementation supports masking of sequences. -
'None': Applies no normalization.
-
-
tf_normalization_position: Position where the normalization should be applied. Allowed values:
-
'pre': Applies normalization before the layers as described by Xiong et al. (2020). -
'post': Applies normalization after the layers as described in the original transformer model.
-
-
tf_parametrizations: Re-Parametrizations of the weights of layers. Allowed values:
-
'None': Does not apply any re-parametrizations. -
'OrthogonalWeights': Applies an orthogonal re-parametrizations of the weights with PyTorchs implemented function using orthogonal_map=‘matrix_exp’. -
'WeightNorm': Applies a weight norm with the default settings of PyTorch’s corresponding function. Weight norm is described by Salimans and Kingma 2016. -
'SpectralNorm': Applies a spectral norm with the default settings of PyTorch’s corresponding function. The norm is described by Miyato et al. 2018.
-
tf_bias: If
TRUEa bias term is added to all layers. IfFALSEno bias term is added to the layers.tf_act_fct: Activation function for the specified layers.
tf_dropout_rate_1: determining the dropout after the attention mechanism within the transformer encoder layers.
tf_dropout_rate_2: determining the dropout for the dense projection within the transformer encoder layers.
tf_num_heads: determining the number of attention heads for a self-attention layer. Only relevant if
attention_type='MultiHead'tf_dense_dim: determining the size of the projection layer within a each transformer encoder.
-
tf_attention_type: Choose the attention type. Allowed values:
-
'multihead': The original multi-head attention as described by Vaswani et al. (2017). -
'fourier': Attention with fourier transformation as described by Lee-Thorp et al. (2021).
-
-
tf_positional_type: Type of processing positional information. Allowed values:
-
'absolute': Adds positional information by using an embedding matrix as described by Chollet, Kalinowski, and Allaire (2022, pp. 378-379). This implementation is different to the original work by Vaswani et al. (2017). -
'None': No absolute positional information is added.
-
tf_n_layers: determining how many times the encoder should be added to the network.
Feature Layer
Visualization
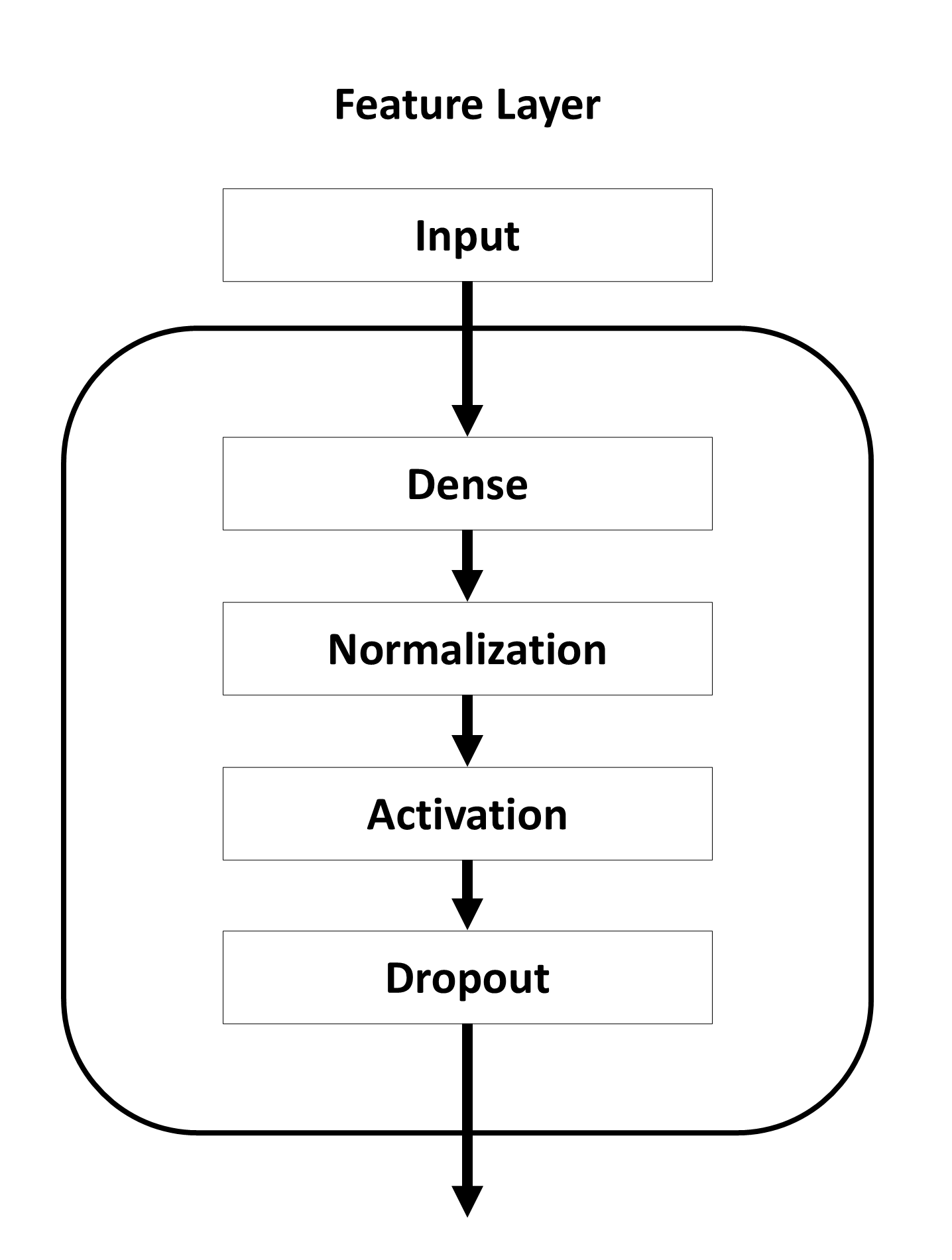
Description
The feature layer is a dense layer that can be used to increase or decrease the number of features of the input data before passing the data into your model. The aim of this layer is to increase or reduce the complexity of the data for your model. The output size of this layer determines the number of features for all following layers. In the special case that the requested number of features equals the number of features of the text embeddings this layer is reduced to a dropout layer with masking capabilities. All parameters with the prefix feat_ can be used to configure this layer.
Parameters
-
feat_normalization_type: Type of normalization applied to all layers and stack layers. Allowed values:
-
'LayerNorm': Applies normalization as described by Ba, Kiros, and Hinton (2016). Implementation supports masking of sequences. -
'BatchNorm': Applies normalization as described by Loffe and Szegedy (2015). Implementation supports masking of sequences. -
'RMSNorm': Applies normalization as described by Zhang and Sennrich (2019). Implementation supports masking of sequences. -
'PowerNorm': Applies normalization as described by Shen et al. (2020). Implementation supports masking of sequences. -
'None': Applies no normalization.
-
-
feat_parametrizations: Re-Parametrizations of the weights of layers. Allowed values:
-
'None': Does not apply any re-parametrizations. -
'OrthogonalWeights': Applies an orthogonal re-parametrizations of the weights with PyTorchs implemented function using orthogonal_map=‘matrix_exp’. -
'WeightNorm': Applies a weight norm with the default settings of PyTorch’s corresponding function. Weight norm is described by Salimans and Kingma 2016. -
'SpectralNorm': Applies a spectral norm with the default settings of PyTorch’s corresponding function. The norm is described by Miyato et al. 2018.
-
feat_bias: If
TRUEa bias term is added to all layers. IfFALSEno bias term is added to the layers.feat_act_fct: Activation function for the specified layers.
feat_dropout: determining the dropout for the dense projection of the feature layer.
feat_size: Number of neurons for each dense layer.
Dense Layers
Visualization
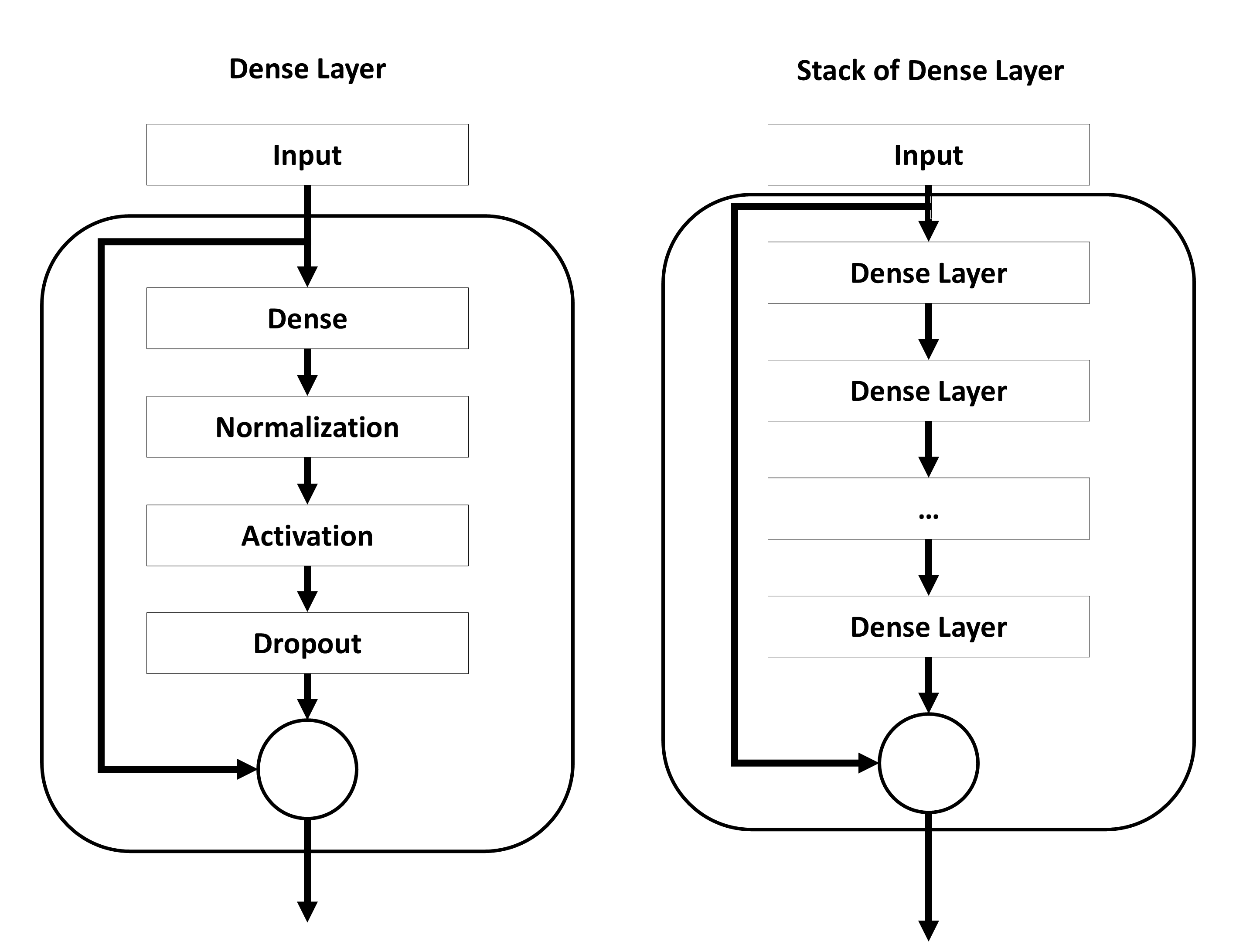
Description
A fully connected layer. The layer is applied to every step of a sequence. All parameters with the prefix dense_ can be used to configure this layer.
Parameters
-
dense_residual_type: Type of residual connenction for all layers and stack of layers. Allowed values:
-
'None': Add no residual connection. -
'Addition': Adds a residual connection by adding the original input to the output. -
'ResidualGate': Adds a residucal connection by creating a weightes sum from the original input and the output. The weight is a learnable parameter. This type of residual connection is described by Savarese and Figueiredo (2017).
-
-
dense_normalization_type: Type of normalization applied to all layers and stack layers. Allowed values:
-
'LayerNorm': Applies normalization as described by Ba, Kiros, and Hinton (2016). Implementation supports masking of sequences. -
'BatchNorm': Applies normalization as described by Loffe and Szegedy (2015). Implementation supports masking of sequences. -
'RMSNorm': Applies normalization as described by Zhang and Sennrich (2019). Implementation supports masking of sequences. -
'PowerNorm': Applies normalization as described by Shen et al. (2020). Implementation supports masking of sequences. -
'None': Applies no normalization.
-
-
dense_parametrizations: Re-Parametrizations of the weights of layers. Allowed values:
-
'None': Does not apply any re-parametrizations. -
'OrthogonalWeights': Applies an orthogonal re-parametrizations of the weights with PyTorchs implemented function using orthogonal_map=‘matrix_exp’. -
'WeightNorm': Applies a weight norm with the default settings of PyTorch’s corresponding function. Weight norm is described by Salimans and Kingma 2016. -
'SpectralNorm': Applies a spectral norm with the default settings of PyTorch’s corresponding function. The norm is described by Miyato et al. 2018.
-
dense_bias: If
TRUEa bias term is added to all layers. IfFALSEno bias term is added to the layers.dense_act_fct: Activation function for the specified layers.
dense_dropout: determining the dropout between dense layers.
dense_size: Number of neurons for each dense layer.
dense_layers: Number of dense layers.
dense_n_layers: Number of dense layers.
Multiple N-Gram Layers
Visualization
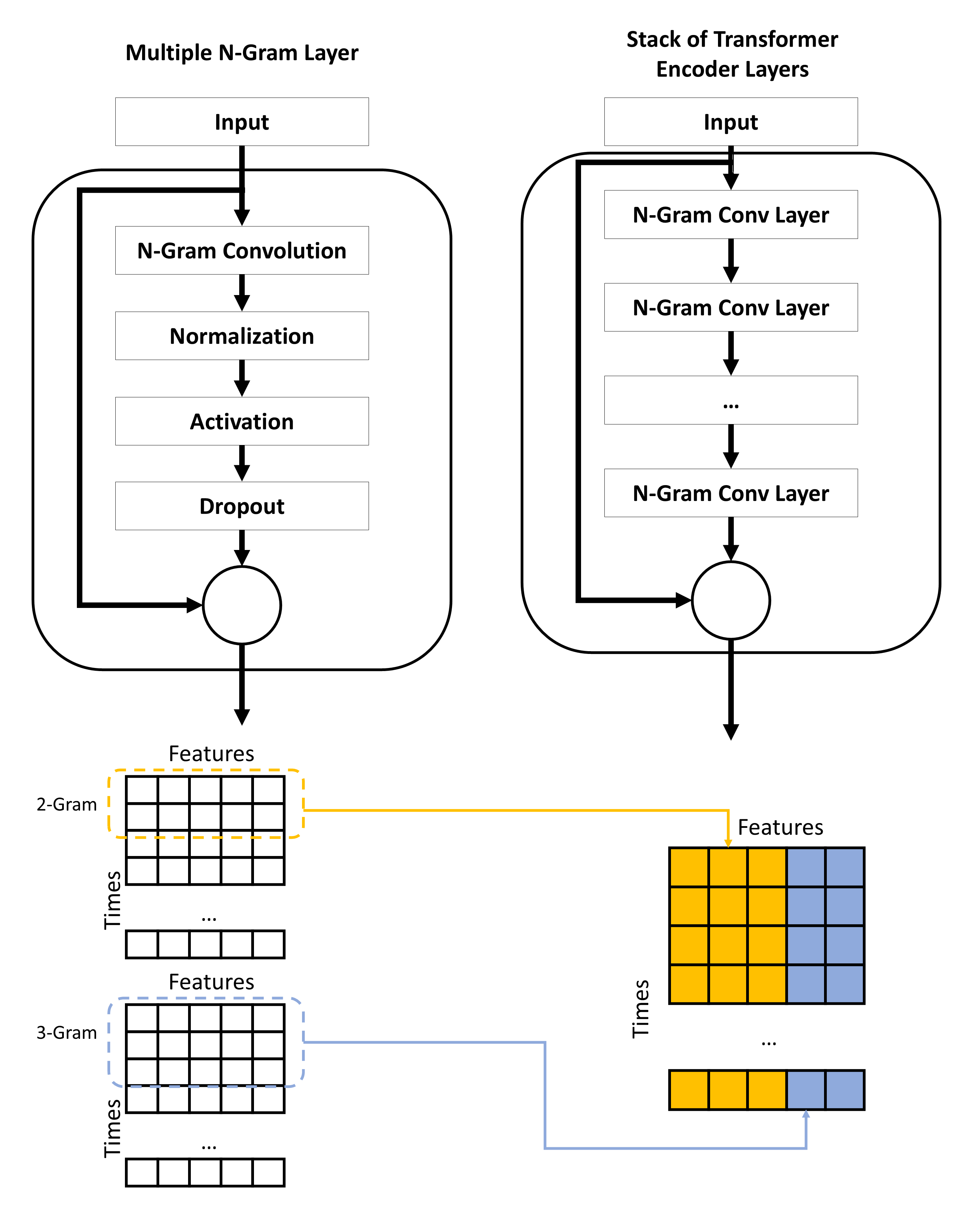
Description
This type of layer focuses on sub-sequence and performs an 1d convolutional operation. On a word and token level these sub-sequences can be interpreted as n-grams (Jacovi, Shalom & Goldberg 2018). The convolution is done across all features. The number of filters equals the number of features of the input tensor. Thus, the shape of the tensor is retained (Pham, Kruszewski & Boleda 2016).
The layer is able to consider multiple n-grams at the same time. In this case the convolution of the n-grams is done seprately and the resulting tensors are concatenated along the feature dimension. The number of filters for each n-gram is set to the next smallest natural number of num_features/num_n-grams. A residual is added to the first n-gram. Thus, the resulting tensor has the same shape as the input tensor.
Sub-sequences that are masked in the input are also masked in the output.
The output of this layer can be understand as the results of the n-gram filters. Stacking this layer allows the model to perform n-gram detection of n-grams (meta perspective). All parameters with the prefix ng_conv_ can be used to configure this layer.
Parameters
-
ng_conv_residual_type: Type of residual connenction for all layers and stack of layers. Allowed values:
-
'None': Add no residual connection. -
'Addition': Adds a residual connection by adding the original input to the output. -
'ResidualGate': Adds a residucal connection by creating a weightes sum from the original input and the output. The weight is a learnable parameter. This type of residual connection is described by Savarese and Figueiredo (2017).
-
-
ng_conv_normalization_type: Type of normalization applied to all layers and stack layers. Allowed values:
-
'LayerNorm': Applies normalization as described by Ba, Kiros, and Hinton (2016). Implementation supports masking of sequences. -
'BatchNorm': Applies normalization as described by Loffe and Szegedy (2015). Implementation supports masking of sequences. -
'RMSNorm': Applies normalization as described by Zhang and Sennrich (2019). Implementation supports masking of sequences. -
'PowerNorm': Applies normalization as described by Shen et al. (2020). Implementation supports masking of sequences. -
'None': Applies no normalization.
-
-
ng_conv_parametrizations: Re-Parametrizations of the weights of layers. Allowed values:
-
'None': Does not apply any re-parametrizations. -
'OrthogonalWeights': Applies an orthogonal re-parametrizations of the weights with PyTorchs implemented function using orthogonal_map=‘matrix_exp’. -
'WeightNorm': Applies a weight norm with the default settings of PyTorch’s corresponding function. Weight norm is described by Salimans and Kingma 2016. -
'SpectralNorm': Applies a spectral norm with the default settings of PyTorch’s corresponding function. The norm is described by Miyato et al. 2018.
-
ng_conv_bias: If
TRUEa bias term is added to all layers. IfFALSEno bias term is added to the layers.ng_conv_act_fct: Activation function for the specified layers.
ng_conv_dropout: determining the dropout for n-gram convolution layers.
ng_conv_n_layers: determining how many times the n-gram layers should be added to the network.
ng_conv_ks_min: determining the minimal window size for n-grams.
ng_conv_ks_max: determining the maximal window size for n-grams.
Recurrent Layers
Visualization
Description
A regular recurrent layer either as Gated Recurrent Unit (GRU) or Long Short-Term Memory (LSTM) layer. Uses PyTorchs implementation. All parameters with the prefix rec_ can be used to configure this layer.
Parameters
-
rec_residual_type: Type of residual connenction for all layers and stack of layers. Allowed values:
-
'None': Add no residual connection. -
'Addition': Adds a residual connection by adding the original input to the output. -
'ResidualGate': Adds a residucal connection by creating a weightes sum from the original input and the output. The weight is a learnable parameter. This type of residual connection is described by Savarese and Figueiredo (2017).
-
-
rec_normalization_type: Type of normalization applied to all layers and stack layers. Allowed values:
-
'LayerNorm': Applies normalization as described by Ba, Kiros, and Hinton (2016). Implementation supports masking of sequences. -
'BatchNorm': Applies normalization as described by Loffe and Szegedy (2015). Implementation supports masking of sequences. -
'RMSNorm': Applies normalization as described by Zhang and Sennrich (2019). Implementation supports masking of sequences. -
'PowerNorm': Applies normalization as described by Shen et al. (2020). Implementation supports masking of sequences. -
'None': Applies no normalization.
-
-
rec_parametrizations: Re-Parametrizations of the weights of layers. Allowed values:
-
'None': Does not apply any re-parametrizations. -
'OrthogonalWeights': Applies an orthogonal re-parametrizations of the weights with PyTorchs implemented function using orthogonal_map=‘matrix_exp’. -
'WeightNorm': Applies a weight norm with the default settings of PyTorch’s corresponding function. Weight norm is described by Salimans and Kingma 2016. -
'SpectralNorm': Applies a spectral norm with the default settings of PyTorch’s corresponding function. The norm is described by Miyato et al. 2018.
-
rec_bias: If
TRUEa bias term is added to all layers. IfFALSEno bias term is added to the layers.rec_act_fct: Activation function for the specified layers.
rec_dropout: determining the dropout between recurrent layers.
rec_type: Type of the recurrent layers.
rec_type='GRU'for Gated Recurrent Unit andrec_type='LSTM'for Long Short-Term Memory.rec_bidirectional: If
TRUEa bidirectional version of the recurrent layers is used.rec_size: Number of neurons for each recurrent layer.
rec_layers: Number of recurrent layers.
rec_n_layers: Number of recurrent layers.
Classifiction Pooling Layer
Visualization
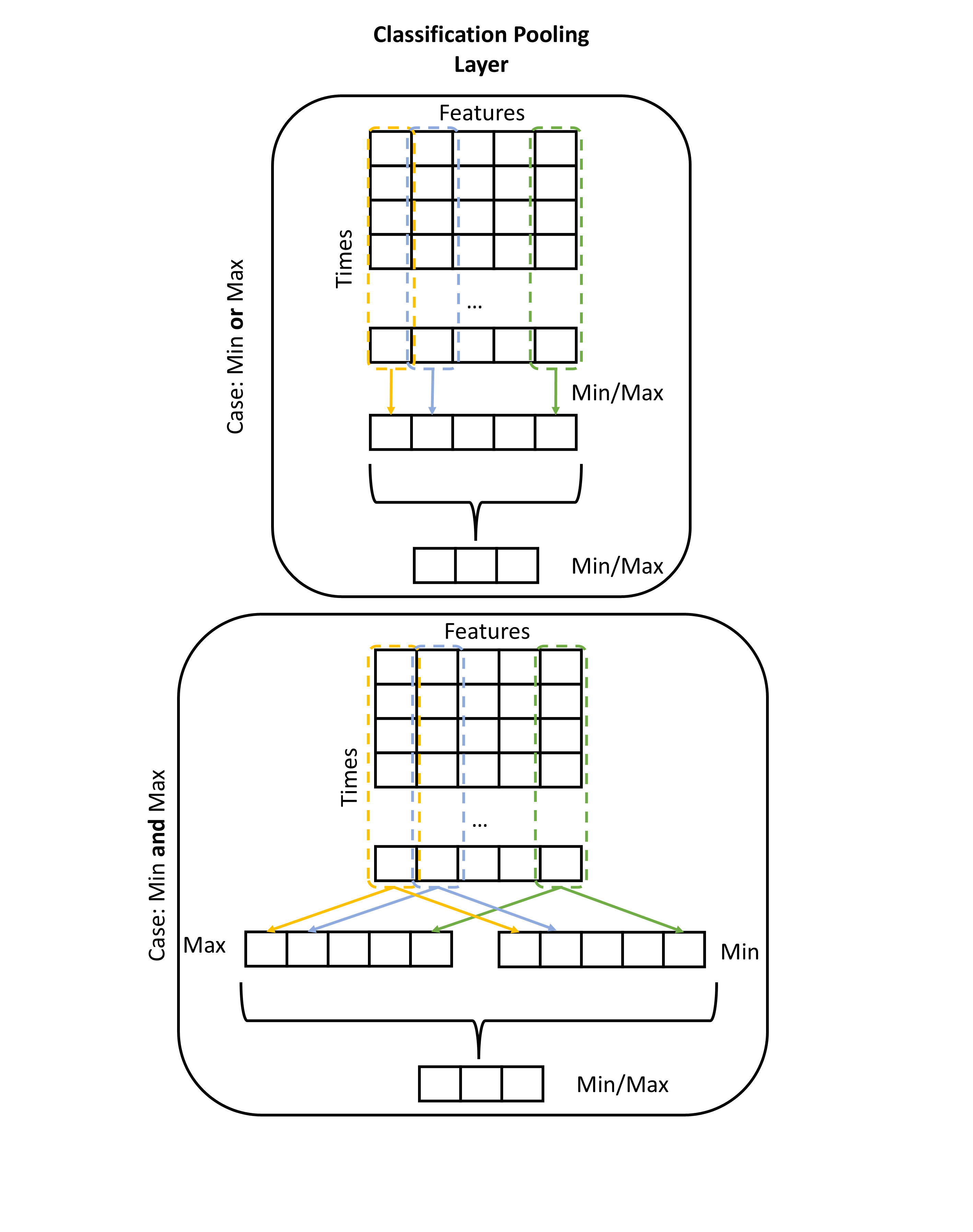
Description
Layer transforms sequences into a lower dimensional space that can be passed to dense layers. It can perform two types of pooling. First, it extractes features across the time dimension selecting the maximal and/or minimal features. Second, it performs pooling over the remaining features selecting a specific number of the heighest and/or lowest features. Pooling over time is mandatory. Pooling over features is optional and can lead to a lose of information.
In the case of selecting the minmal and maximal features at the same time the minmal features are concatenated to the tensor of the maximal features resulting in the shape (Batch, Times, 2*Features) at the end of the first step. In the second step the number of requested features is halved. The first half is used for the maximal features and the second for the minimal features. All parameters with the prefix cls_pooling_ can be used to configure this layer.
Parameters
cls_pooling_features: Number of features to be extracted at the end of the model. Only relevant if pooling type is ‘Max’, ‘Min’ or ‘MinMax’.
cls_pooling_type: Type of extracting intermediate features.
Merge Layer
Visualization
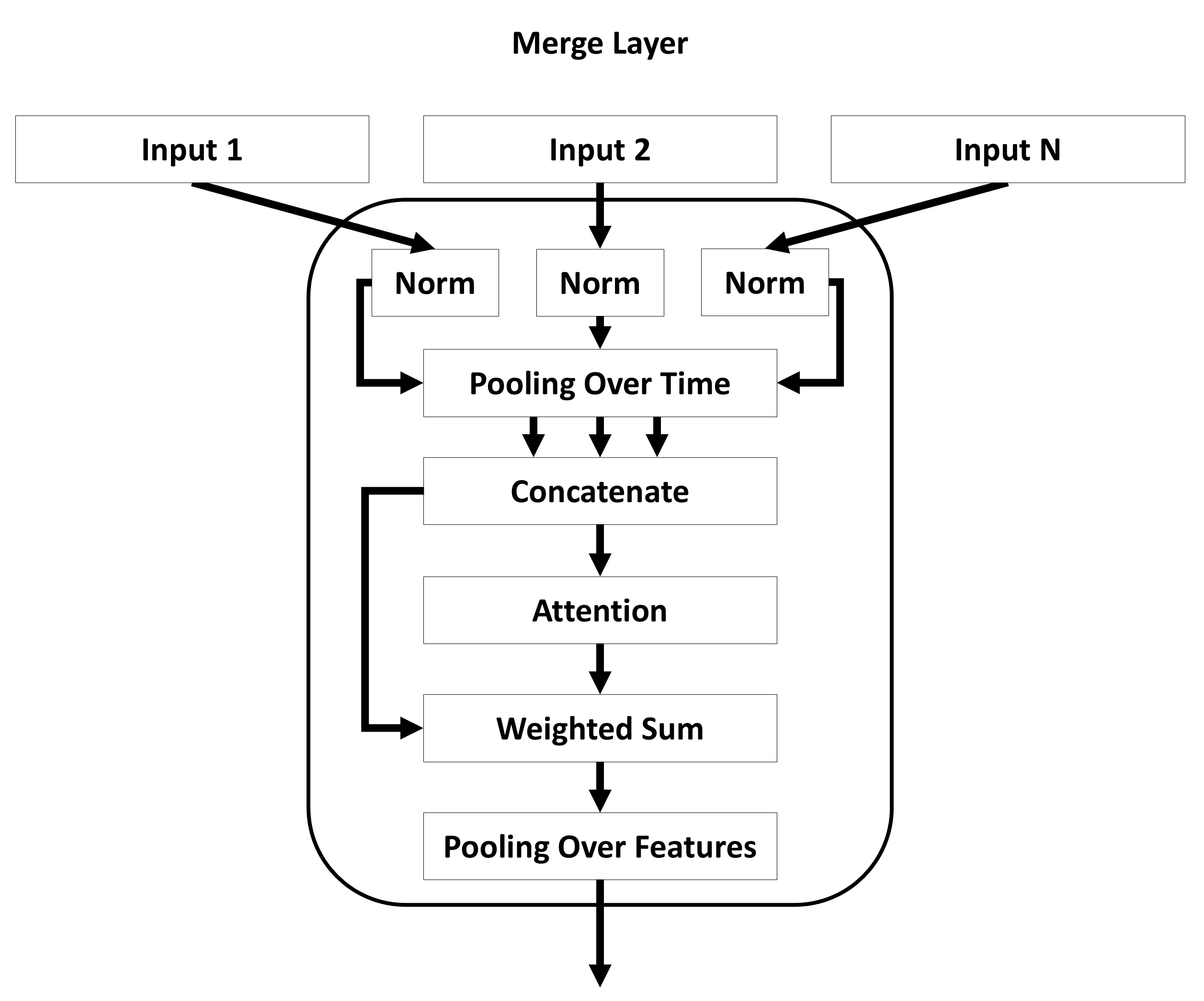
Description
Layer for combining the output of different layers. All inputs must be sequential data of shape (Batch, Times, Features). First, pooling over time is applied extracting the minimal and/or maximal features. Second, the pooled tensors are combined by calculating their weighted sum. Different attention mechanism can be used to dynamically calculate the corresponding weights. This allows the model to decide which part of the data is most usefull. Finally, pooling over features can be applied extracting a specific number of maximal and/or minimal features. Pooling over times is mandatory. Pooling over features is optional and can lead to a lose of information.
A normalization of all input at the begining of the layer is possible. All parameters with the prefix *merge_* can be used to configure this layer.Parameters
-
merge_normalization_type: Type of normalization applied to all layers and stack layers. Allowed values:
-
'LayerNorm': Applies normalization as described by Ba, Kiros, and Hinton (2016). Implementation supports masking of sequences. -
'BatchNorm': Applies normalization as described by Loffe and Szegedy (2015). Implementation supports masking of sequences. -
'RMSNorm': Applies normalization as described by Zhang and Sennrich (2019). Implementation supports masking of sequences. -
'PowerNorm': Applies normalization as described by Shen et al. (2020). Implementation supports masking of sequences. -
'None': Applies no normalization.
-
merge_pooling_features: Number of features to be extracted at the end of the model. Only relevant if pooling type is ‘Max’, ‘Min’ or ‘MinMax’.
merge_pooling_type: Type of extracting intermediate features.
-
merge_attention_type: Choose the attention type. Allowed values:
-
'multihead': The original multi-head attention as described by Vaswani et al. (2017). -
'fourier': Attention with fourier transformation as described by Lee-Thorp et al. (2021).
-
merge_num_heads: determining the number of attention heads for a self-attention layer. Only relevant if
attention_type='MultiHead'